¿Qué es RAID? Orígenes, Explicación, Componentes y Configuraciones
-
 Escrito por Kees Jan Meerman
Escrito por Kees Jan Meerman -
 Actualizado el Mar 03, 2026
Actualizado el Mar 03, 2026 -
 Min Lectura 4 Min
Min Lectura 4 Min - Comparte
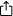
Breve historia de RAID
Antes de que las matrices de almacenamiento modernas y las unidades en la nube se convirtieran en herramientas cotidianas, las empresas se enfrentaban a un reto fundamental: cómo almacenar cantidades cada vez mayores de datos de forma fiable y rentable
Los sistemas de almacenamiento tenían que seguir el ritmo de los rápidos avances de los procesadores y de las aplicaciones empresariales cada vez más exigentes, pero les costaba hacerlo.
A mediados de la década de 1980, todos los centros de datos importantes seguían dependiendo de unidades únicas, grandes y costosas (SLED).
- El producto estrella de IBM, la carcasa 3380, tenía una capacidad de unos 2,52 GB, alcanzaba una velocidad de transferencia de 3 MB/s, tenía un tiempo medio de búsqueda de 16 ms y costaba entre 81 000 y 142 000 libras esterlinas, además de un metro cúbico de espacio y un kilovatio de potencia.

- Los ordenadores más pequeños no estaban mejor: el primer disco duro para PC, el ST-506 de 5,25 pulgadas de Shugart Technology (ahora Seagate), tenía una capacidad de solo 5 MB y costaba 1500 libras, lo que suponía la friolera de 300 libras por MB.

Al mismo tiempo, la ley de Moore se aplicaba a las CPU y a las DRAM, cada vez más baratas, cuya velocidad o capacidad se duplicaba cada 18 o 24 meses, sin apenas cambios. Esto significaba que el procesamiento de transacciones, las bases de datos SQL y las nuevas aplicaciones cliente-servidor realizaban muchas más operaciones de E/S aleatorias y minúsculas de las que podía manejar un solo eje.
Investigadores de la Universidad de California en Berkeley —David Patterson, Garth Gibson y Randy Katz— cuantificaron la diferencia: el rendimiento de los procesadores aumentaba un 40 % al año, mientras que la latencia mecánica de un disco duro de gama alta apenas mejoraba un 7 % al año.
El resultado fue una inminente «crisis de E/S»: las CPU se paralizaron, las ventanas de lotes superaron los plazos y las empresas se vieron obligadas a distribuir tablas críticas entre cientos de SLED.
Esta solución rápida y temporal causó nuevos problemas.
- Los costes aumentaban de forma lineal con cada SLED adicional.
- La disponibilidad incluso disminuyó, ya que más ejes significaban más fuentes de fallo.
- Los operadores libraron una batalla perdida contra el calor, el consumo de energía y la falta de espacio.
Lo que la industria necesitaba con urgencia era un rendimiento y una capacidad similares a los de los mainframes, pero a precios de PC, sin comprometer la fiabilidad.
Fueron precisamente estas limitaciones las que inspiraron a la comunidad investigadora en el ámbito del almacenamiento en la década de 1980.
RAID: origen y definición
A finales de 1987, Patterson, Gibson y Katz instalaron una mesa plegable en un laboratorio de la Universidad de California en Berkeley con diez unidades de PC Conner CP-3100 de 100 MB conectadas a un controlador SCSI estándar.

Estaban investigando una pregunta: ¿Podría un conjunto de discos duros de PC económicos superar al principal ordenador central de la época, el IBM 3380?
Su publicación SIGMOD de 1988, «A Case for Redundant Arrays of Inexpensive Disks (RAID)», aportó datos contundentes.
| Drive (1987) | Capacidad | Velocidad de transferencia | Precio/MB | Rendimiento | Capacidad de almacenamiento |
|---|---|---|---|---|---|
| IBM 3380 AK4 | 7500 MB | ≈ 3 MB/s | 18 | 6,6 kW | 24 pies |
| Fujitsu «Super Eagle» | 600 MB | ≈ 2,5 MB/s | 20–17 | 64 | 3,4 |
| Conner CP-3100 | 1000 MB | ≈ 1 MB/s | 11–7 | 1 | 0,03 |
A continuación, modelaron una matriz RAID de nivel 5 compuesta por 100 de estas unidades Conner (10 de datos + 2 de paridad por grupo).
El resultado:
- Aproximadamente cinco veces más rendimiento de E/S, rendimiento y ahorro de espacio en comparación con el IBM 3380
- Reducción del coste por gigabyte en dos órdenes de magnitud
- Mayor fiabilidad calculada gracias a la paridad y la recuperación de repuestos en caliente
En otras palabras, una matriz con un valor de 11 000 £ alcanzó, y a menudo superó, el SLED de 100 000 £ en todos los indicadores clave de rendimiento.
Esta demostración transformó el RAID de una idea en una realidad y marcó el comienzo de la era de la tecnología de matrices.
Qué significa el nombre «matriz redundante de discos independientes»
| Palabra | Por qué es importante |
|---|---|
| Redundante | Se almacena información adicional (copias completas o códigos de paridad) para que los datos lógicos permanezcan en línea tras un fallo de la unidad. |
| Matriz | Muchas unidades físicas se virtualizan en un espacio de direcciones lógicas; el administrador asigna números de bloque de host a ubicaciones de unidades/sectores, ordena la E/S y coordina la recuperación |
| Independiente (originalmente «rentable») | Los discos duros estándar fallan de forma independiente entre sí y son mucho menos costosos por GB que un SLED monolítico. El controlador RAID compensa esta mayor tasa de fallos, lo que garantiza un MTTDL (tiempo medio de pérdida de datos) más alto para el sistema. |
| Discos duros | El esquema se desarrolló para discos duros giratorios, pero también se puede aplicar a SSD y otras unidades. |
Por lo tanto, un conjunto RAID es un único disco duro virtual que se presenta al host y consta de un grupo de unidades económicas y propensas a fallos con suficiente lógica de redundancia para garantizar la integridad de los datos y lograr un rendimiento general más alto.
Antes de profundizar en los niveles RAID específicos, necesitamos tres componentes técnicos básicos (striping, mirroring y paridad), así como algunos términos básicos.
- E/S (entrada/salida): cualquier solicitud de lectura o escritura emitida por el host.
- Host: el servidor o la entidad responsable de enviar solicitudes de bloques a través de SAS, SATA, NVMe o FC.
- Bloque (sector): unidad atómica (512 B-4 KiB) en la que los discos duros almacenan datos y los algoritmos RAID calculan la paridad.
Con este vocabulario, ahora podemos ver cómo el striping acelera la E/S, cómo el mirroring proporciona redundancia instantánea y cómo la paridad nos permite recuperar los datos perdidos utilizando la elegante matemática XOR.
Los tres pilares de RAID: striping, mirroring y paridad
Distribución (rendimiento y escalabilidad)
La distribución en bandas es una técnica en la que los datos se distribuyen entre varias unidades para que puedan funcionar en paralelo. Todos los cabezales de lectura/escritura funcionan simultáneamente en los discos correspondientes, lo que permite procesar más datos en menos tiempo. Esto aumenta significativamente el rendimiento en comparación con un solo disco duro.
El siguiente diagrama muestra cómo funciona la distribución en un conjunto de unidades W. Una banda consta de N bloques contiguos en una unidad; una banda es el conjunto de bandas alineadas que abarca W unidades (el ancho de la banda).
Tamaño de la banda = tamaño de la tira × ancho de la banda.
La elección del tamaño de la banda es una cuestión puramente relacionada con la optimización de la carga de trabajo. Puede ser pequeño (16-64 KiB) para OLTP (procesamiento de transacciones en línea) o grande (256 KiB-1 MiB) para transmisiones de vídeo.
Al procesar cada solicitud de E/S en paralelo con varios discos duros, el ancho de banda secuencial se escala de forma casi lineal con W hasta que se utiliza por completo el controlador o el bus.
La configuración RAID con striping puro (es decir, sin duplicación) es RAID 0, que no ofrece redundancia: si falla un miembro, se pierde toda la matriz.
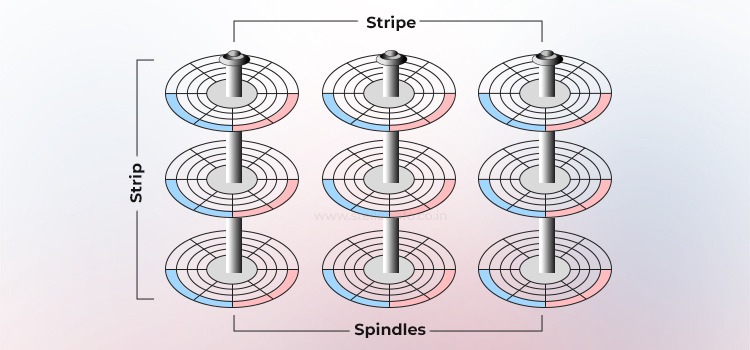
Duplicación (redundancia inmediata)
El espejo es una técnica en la que los mismos datos se almacenan en dos unidades de disco duro diferentes. Si falla una unidad de disco duro, los datos del disco duro intacto se conservan por completo. La parte responsable sigue atendiendo las solicitudes de datos del host sin interrupción a través del miembro intacto del par espejado.
Cuando se sustituye el disco duro averiado por uno nuevo, la parte responsable copia automáticamente los datos del disco duro intacto al nuevo, un proceso que es transparente para el host.
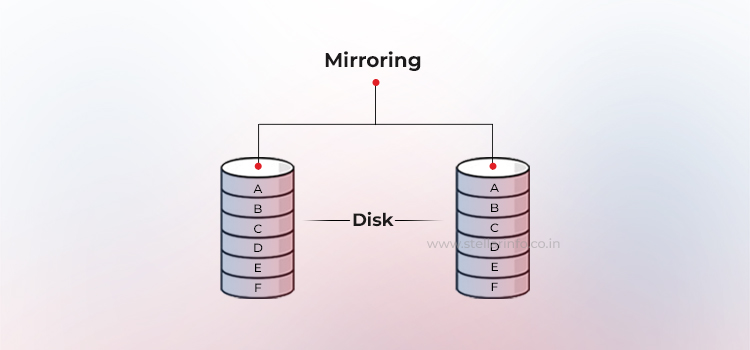
En una configuración RAID duplicada (RAID 1), cada operación de escritura se envía al menos a dos unidades. Esto crea conjuntos de datos duplicados, conocidos como subespejos. La parte responsable puede realizar operaciones de lectura desde el subespejo menos ocupado.
Los sistemas operativos empresariales y los HBA (adaptadores de bus host) ofrecen incluso políticas de lectura circular o geométrica para equilibrar la carga y reducir el tiempo de búsqueda.
Aunque la duplicación implica una ligera latencia para los comandos de escritura (que deben ejecutarse dos veces) y la eficiencia de la capacidad es del 50 %, las ventajas superan a las desventajas: en caso de fallo de una unidad, la recuperación es trivial, basta con copiar el miembro intacto a una unidad de sustitución.
Paridad (redundancia basada en matemáticas)
La paridad es un método para proteger los datos distribuidos en bandas contra fallos del disco duro sin incurrir en el coste total de la duplicación. En lugar de duplicar todos los datos, las matrices RAID utilizan un disco duro adicional (o espacio de almacenamiento distribuido) para almacenar la paridad, un resumen matemático de los datos que permite al sistema reconstruir la información perdida.
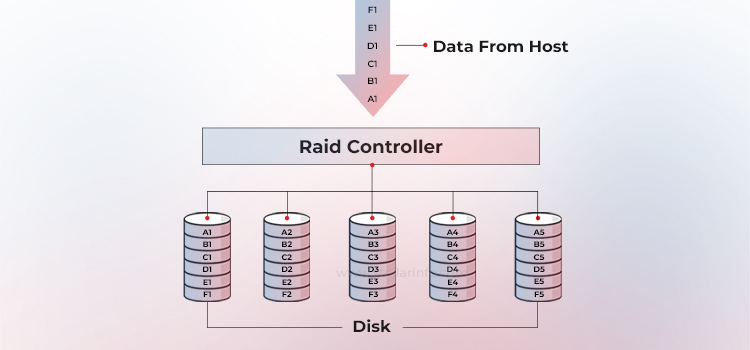
El controlador RAID calcula esta paridad mediante una operación XOR bit a bit en todos los bloques de datos de una banda. Si falla una unidad, el bloque que falta se puede recuperar inmediatamente aplicando la operación XOR a los datos restantes con la paridad almacenada.
Consideremos, por ejemplo, tres bits: A, B y C, donde A es la paridad generada a partir de B y C. Así es como funciona XOR:
| B | A | A = B ⊕ C |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Si conoce A y B o C, siempre podrá recuperar el tercer elemento. Este es el principio de paridad que utiliza RAID para recuperar bloques de datos perdidos.
La información de paridad se puede almacenar en un disco duro dedicado (RAID 4) o distribuirse entre todos los miembros (RAID 5). RAID 6 va un paso más allá y añade un segundo bloque de paridad, lo que permite la recuperación de datos en caso de dos fallos simultáneos. La desventaja es una pequeña sobrecarga de escritura: cada vez que hay una actualización, se cambian tanto los datos originales como la paridad, lo que requiere ciclos adicionales de lectura, modificación y escritura que afectan al rendimiento.
RAID es un marco: cada nivel resuelve un problema diferente
Así pues, la publicación de Berkeley de 1988 no solo acuñó un acrónimo, sino que definió un marco para escalar los sistemas de almacenamiento en tres ejes: rendimiento, eficiencia de la capacidad y tolerancia a fallos.
- El striping puro sin redundancia se convirtió en RAID 0.
- Al añadir la duplicación completa se obtiene RAID 1, que da prioridad a la disponibilidad sobre los terabytes utilizables.
- La combinación de la distribución con la paridad matemática da lugar a las configuraciones RAID 5 y 6, que sacrifican algo de velocidad de escritura para sobrevivir al fallo de una o incluso dos unidades.
Cada configuración es simplemente un punto diferente en el espacio registrado por el documento SIGMOD de 1988.
Lee más artículos para profundizar tus conocimientos sobre RAID y recuperación de datos:


Acerca del autor



