¿Qué es RAID 1? Características, Funcionamiento, Ventajas, Limitaciones y Escenarios de Implementación
-
 Escrito por Kees Jan Meerman
Escrito por Kees Jan Meerman -
 Actualizado el May 22, 2026
Actualizado el May 22, 2026 -
 Min Lectura 4 Min
Min Lectura 4 Min - Comparte
Cuando Patterson, Gibson y Katz presentaron RAID en su publicación de 1988, la demostración probó que el striping de una serie de discos duros de PC económicos podía superar en rendimiento a un IBM 3380 de 100 000 libras.
Lo que no demostró fue la capacidad de supervivencia: con un solo disco averiado, todo el arreglo colapsó. Por ello, los autores dirigieron a los lectores hacia un método de protección que ya había sido probado mucho antes de que existiera el término RAID: la duplicación de discos (mirroring).
- Años 70: Los mainframes Tandem NonStop tenían dos unidades idénticas en rutas de E/S separadas, por lo que un solo fallo nunca interrumpía el flujo de transacciones.
- 1977: Una patente de IBM (Ken Ouchi) describía las «copias sombra» en dos discos duros idénticos para garantizar la integridad de los datos.
- 1983: DEC HSC50 lanzó los subsistemas RA8x con duplicación a nivel de controlador, el primer producto comercial que hoy llamaríamos RAID 1.
Los investigadores de Berkeley formalizaron esta práctica como Nivel 1 en la nueva taxonomía RAID (o RAID 1) de una manera sencilla y, además, la combinaron con el striping de Nivel 0 (o RAID 0) para cubrir tanto el rendimiento como la disponibilidad.
¿Es nuevo en nuestra serie sobre servidores y matrices RAID?
Empiece por leer nuestra introducción, «¿Qué es RAID?», para comprender el striping, el mirroring y la paridad, los tres conceptos en los que se basan todos los niveles RAID.
Una vez sentadas estas bases, veamos ahora qué significa realmente el término RAID 1, cómo funciona entre bastidores y por qué se ha convertido en la solución estándar para los datos que deben permanecer en línea incluso en caso de fallo del disco duro.
Cómo funciona realmente RAID 1: diseño, mecánica y rendimiento
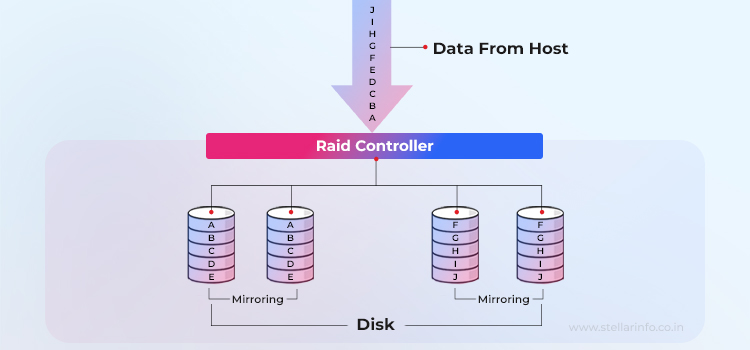
- La solicitud de E/S del host llega al controlador RAID. El servidor trata toda la matriz como un único disco duro lógico y comienza a escribir.
- El controlador duplica cada operación de escritura. Cada bloque (A, B, C... en el diagrama) se envía a ambas unidades del conjunto de espejos. Esta duplicación es transparente para el host; no se requieren cambios en el controlador ni en la aplicación.
- Ambos discos duros pueden realizar operaciones de lectura. Para una solicitud de lectura, el controlador puede seleccionar el miembro con los cabezales más cercanos, lo que reduce el tiempo de búsqueda y, con HBA (adaptadores de bus host) inteligentes, casi duplica las IOPS (operaciones de entrada/salida por segundo) para operaciones de lectura aleatorias.
- Si una unidad falla, el controlador utiliza la unidad de socio que sigue funcionando de forma sencilla. Dado que los datos ya están completamente presentes en este disco duro, la pérdida de datos es mínima en comparación con todos los demás niveles RAID: sin cálculos de paridad ni largos procesos de recuperación.
- Cuando se sustituye la unidad averiada (o se dispone de una unidad de repuesto en caliente), la persona responsable realiza una operación de clonación secuencial desde el disco duro intacto al nuevo disco duro, tras lo cual se reanuda el mirroring normal.
Por lo tanto, RAID 1 es la configuración canónica de pares de espejos: cada bloque escrito por el host se almacena en dos unidades independientes, de modo que siempre hay dos copias idénticas disponibles. Si una de las dos unidades falla, la unidad restante sigue suministrando los datos sin interrupción. Dado que solo uno de los dos pares de espejos tiene que seguir funcionando, la tolerancia a fallos de la matriz es de una unidad por par. Sin embargo, la capacidad es solo la mitad de la capacidad total original.
GB utilizables = n×d / 2
RAID 1: Ruta de escritura y latencia
Con RAID 1, cada operación de escritura del host se duplica. La parte responsable (hardware o software) emite dos comandos de E/S y solo confirma la finalización después de que la unidad de disco duro más lenta de las dos haya informado del éxito. Dado que las operaciones de escritura se realizan en paralelo, la latencia de extremo a extremo es esencialmente la misma que la de una sola unidad de disco duro; no hay retrasos adicionales de búsqueda o rotación más allá de los que ya están presentes en cada unidad.
RAID 1: Ruta de lectura y rendimiento
Para las operaciones de lectura, el controlador RAID 1 puede seleccionar cualquiera de los dos discos duros.
Los HBA inteligentes alternan las solicitudes utilizando un método round-robin o el principio del tiempo de búsqueda más corto, de modo que ambos cabezales pueden trabajar simultáneamente. Cuando se habilita este equilibrio de carga, las IOPS para operaciones de lectura aleatoria pueden ser casi el doble que con una sola unidad. Sin embargo, el firmware sencillo o antiguo trata el espejo como un único dispositivo y logra poca o ninguna mejora en el rendimiento.
RAID 1: gestión de errores, repuestos en caliente y recuperaciones
- Cuando un disco duro se desconecta en RAID 1, el volumen virtual sigue siendo óptimo; el controlador redirige fácilmente todas las operaciones de E/S a la unidad que sigue funcionando.
- Si hay disponible una unidad de repuesto en caliente (una unidad en modo de espera que está lista para sustituir a una unidad averiada), se reclama automáticamente y una resincronización en segundo plano copia todos los bloques del miembro intacto a la unidad de sustitución, sin cálculo de paridad, simplemente como un clon secuencial.
- El tiempo de recuperación es igual al volumen de la unidad dividido por la velocidad de transferencia sostenida; para unidades SATA de 4 TB, esto supone unas pocas horas.
En resumen, RAID 1 sacrifica la mitad de su capacidad bruta a cambio de la certeza de que una sola unidad nunca provocará la pérdida de datos, mientras que los controladores bien ajustados siguen alcanzando un rendimiento de lectura casi equivalente al de RAID 0.
Sin embargo, en casos raros en los que ambos discos espejados fallan o el controlador RAID está dañado, los servicios de recuperación de datos RAID pueden ser esenciales para restaurar datos críticos.
A continuación, compararemos estas ventajas y costes con RAID 0 y los demás niveles clásicos.
Por qué los arquitectos de soluciones de almacenamiento eligen RAID 1 (y por qué no lo hacen)
La única ventaja de RAID 1 es clara: la matriz sigue funcionando incluso si falla una unidad. Sin embargo, esta fiabilidad se consigue a expensas de la capacidad y (a veces) de la velocidad de escritura. A continuación se muestra el equilibrio práctico que se obtiene al cambiar RAID 0 con striping puro por redundancia duplicada.
Observe en la tabla comparativa siguiente cómo RAID 1 pasa de «sin estrellas» a una calificación de cuatro estrellas en tolerancia a fallos, pero cae al 50 % de utilización del almacenamiento, exactamente la mitad de sus terabytes brutos.
| Nivel RAID | Tolerancia a fallos | Rendimiento aleatorio | Rendimiento secuencial | Utilización |
| 0 | ★☆☆☆ | ★★★★☆ | ★★★★☆ | 100 |
| 1 | ★★★★ | ★★★☆☆ | ★★☆☆☆ | 5 |
Ventajas netas de RAID 1
- Disponibilidad constante: un único fallo no supone ningún problema; los usuarios no notarán nada.
- Recuperaciones predecibles: la resincronización es simplemente una copia fácil; 4 TB a 200 MB/s SATA tarda unas 6 horas, no días.
- Velocidad de lectura: con un controlador inteligente, la tasa de IOPS para lecturas aleatorias puede ser casi el doble que la de una sola unidad, ya que ambos cabezales pueden procesar cada solicitud.
Las concesiones inevitables
- Se pierde el 50 % de la capacidad bruta: los datos duplicados, por definición, se pagan dos veces.
- El rendimiento de escritura es equivalente al del miembro más lento; cada confirmación espera a dos discos duros.
- El coste por terabyte protegido es el más alto entre los niveles estándar.
- Sigue sin haber copia de seguridad: la corrupción, el ransomware o los borrados accidentales se duplican inmediatamente; sigue siendo necesario disponer de instantáneas o copias externas.
Por lo tanto, RAID 1 ocupa un nicho muy específico: conjuntos de datos pequeños y medianos cuyo valor supera con creces el coste de la capacidad bruta, y cargas de trabajo en las que la velocidad de lectura y la disponibilidad continua son más importantes que el rendimiento de escritura.
RAID 1: casos de uso y limitaciones
El punto óptimo para RAID 1 es cualquier carga de trabajo en la que el valor empresarial supere con creces el coste de la capacidad bruta y en la que no se tolere el tiempo de inactividad. Dado que cada bloque se duplica inmediatamente, un espejo compensa el fallo de un disco duro sin interrupciones y casi sin degradación del rendimiento.
Casos de uso ideales
- Volúmenes de arranque de sistemas operativos e hipervisores: incluso un fallo breve puede paralizar docenas de máquinas virtuales; proveedores como Oracle recomiendan RAID 1 de hardware para el LUN del sistema en servidores x86 y SPARC.
- Registros de rehacer/diario de la base de datos: la latencia es más importante que la capacidad, y los registros deben sobrevivir a un fallo para que el motor pueda seguir funcionando correctamente.
- Recursos compartidos NAS pequeños pero esenciales: bibliotecas de fotos, archivos de oficina, máquinas virtuales de laboratorio doméstico, etc.
- Informes con uso intensivo de lectura o cachés web: los HBA inteligentes pueden servir lecturas paralelas de ambos miembros, lo que proporciona casi el doble de rendimiento IOPS en lecturas aleatorias desde una sola unidad, al tiempo que se mantiene una disponibilidad del 99,999 %.
- Nodos NVMe Los proveedores de la nube aún recomiendan un par espejado para protegerse contra una falla de SSD repentina cuando no existe un conjunto con paridad
Escenarios que se deben evitar
- Archivos o bibliotecas de vídeo a escala de petabytes: la duplicación consume el 50 % de cada terabyte; la codificación de borrado o las matrices de paridad reducen la sobrecarga de protección al 20-33 %.
- Análisis intensivos en escritura: cada escritura lógica se convierte en dos escrituras físicas, lo que reduce a la mitad las IOPS del backend; RAID de paridad o RAID 10 ofrecen una mejor relación precio/rendimiento para grandes escalas.
- Niveles de almacenamiento en frío donde cada dólar/GB cuenta: los costes de hardware son el doble que con RAID 5/6, pero los requisitos de disponibilidad suelen cumplirse con réplicas en línea o copias de seguridad externas.
En resumen, RAID 1 es un seguro para conjuntos de datos pequeños y medianos en los que la pérdida es inaceptable y los patrones de acceso se basan en gran medida en la lectura. Cuando la eficiencia de la capacidad o el rendimiento de escritura son primordiales, la duplicación da paso a RAID 10 anidado, bandas de paridad o códigos de borrado para el almacenamiento de objetos.
Más allá del simple espejado: ¿qué viene después de RAID 1?
RAID 1 resolvió el problema del fallo de un solo disco duro, pero las matrices más grandes pronto requirieron más ancho de banda por eje o protección contra más de un fallo. Por lo tanto, los proveedores y los núcleos de código abierto combinaron la duplicación con el striping y, posteriormente, reorganizaron los espejos dentro de diseños más grandes y con capacidad de autorreparación.
Un ejemplo de ello son los espejos con bandas o RAID 10 (también conocido como RAID 1 + 0). Se toman varios pares espejados y se dividen en bandas. Las operaciones de lectura y escritura se equilibran entre todos los espejos, por lo que el rendimiento escala de forma casi lineal con el número de pares, mientras que un fallo de un solo disco duro —y a menudo varios, siempre que los discos duros afectados estén en pares diferentes— deja el volumen en línea.
Los conjuntos duplicados, ya sean RAID 1 clásicos o espejos seccionados (RAID 10), siguen siendo inigualables en lo que respecta a la conmutación por error instantánea y la latencia predecible. Sin embargo, consumen la mitad de cada terabyte y solo protegen contra fallos de hardware.
El siguiente salto fue mantener la velocidad de striping, pero sustituir las copias de bloques completos por paridad matemática, lo que redujo la sobrecarga al 20-33 % y permitió el fallo de dos unidades o incluso de nodos completos. Esta historia comienza con RAID 5 y RAID 6.
Nota importante
Incluso con los pares espejados de RAID 1, fallos de hardware inesperados, fallas simultáneas de discos o problemas del controlador pueden poner tus datos en grave riesgo. En tales casos, Recuperación de Datos Stellar ofrece servicios expertos de recuperación de datos RAID para ayudarte a recuperar información crítica con la máxima seguridad y confidencialidad.
Lee artículos relacionados sobre problemas con los discos duros, causas de la pérdida de datos y métodos de recuperación
- Unidades de Disco Duro: Componentes del Tiempo de Acceso y la Velocidad de Transferencia de Datos
- ¿Fallo de RAID? No Confíes en el Servicio de Ayuda de la Marca: Actúa Rápido o Arriesga una Pérdida de Datos Permanente
- Unidades de Disco Duro: Mejoras en Características Clave de Rendimiento a lo Largo de las Décadas
- ¿Cómo afecta la moderna tecnología de discos duros a la sustitución de las placas de circuitos


Acerca del autor



